在统计遗传学和基因组学领域,我们观察到两种显著的发展趋势,它们代表了这个学科的深度和广度。
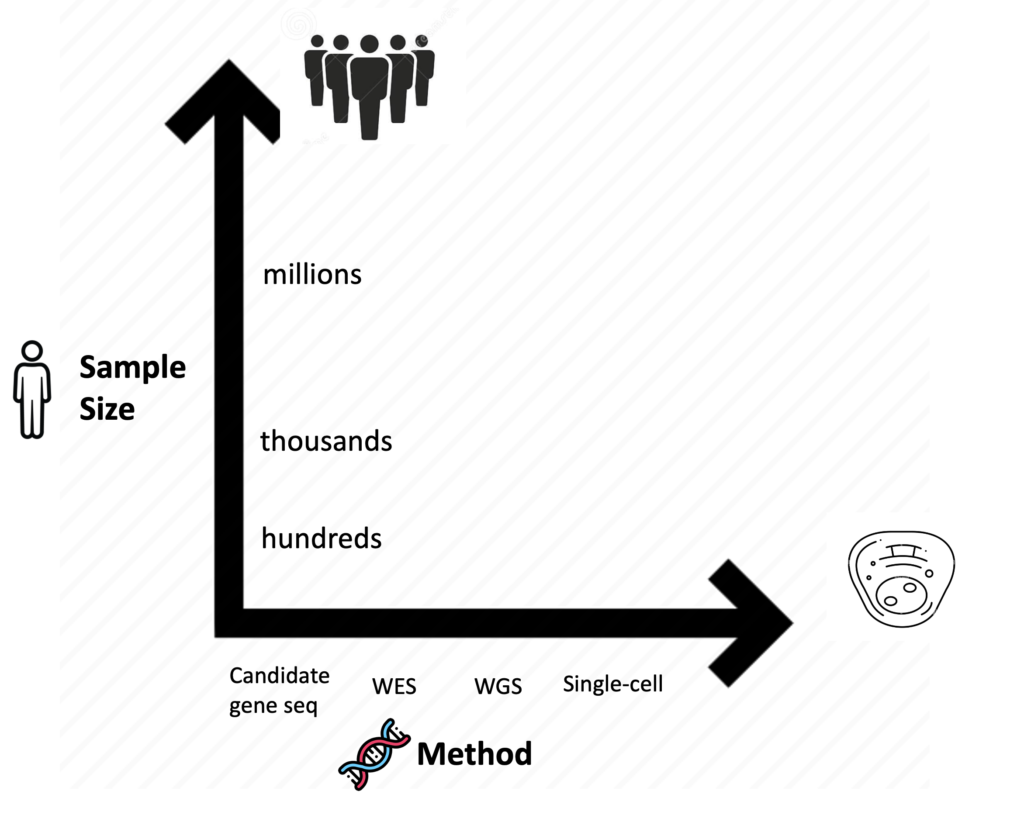
首先,研究的人群规模正在显著扩大。特别是在全基因组关联研究(GWAS)中,我们已经能够看到涵盖数百万人的庞大研究样本。这种规模的增加不仅提高了我们发现遗传变异与特定疾病或特征相关性的能力,而且也加强了统计力,使我们能够识别更加细微的遗传影响。 另一方面,对于个体样本研究的精细程度也在显著提升。从全基因组测序(WGS)到单细胞测序技术,科学家们现在能够在个体水平上进行更深入的遗传分析。这种方法不仅可以揭示个体基因组的复杂性,还能帮助我们理解在不同细胞类型和发育阶段中基因如何不同地表达和调控。单细胞测序技术特别在揭示肿瘤异质性、组织微环境以及发育生物学中的细胞命运决定等领域显示出其独特的价值。 总体而言,这两个趋势——大规模人群研究和个体水平的精细分析——共同推动了统计遗传学和基因组学领域的快速发展,为我们提供了从宏观到微观的全面遗传视角,但同时也对研究人员的综合能力提出了越来越高的要求。
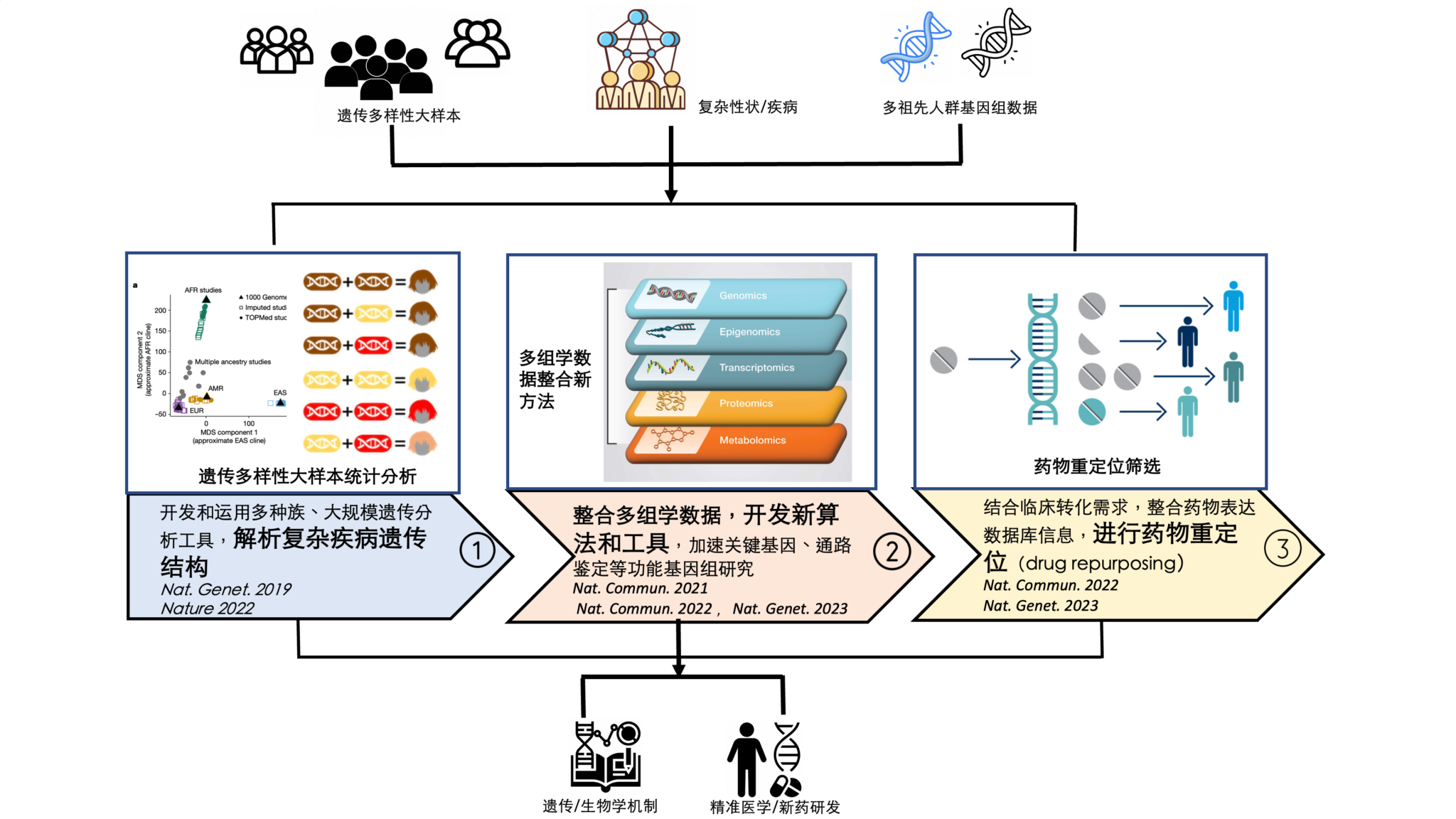
人类多基因复杂疾病(complex disease)是现代遗传学的核心问题之一。 陈放教授在前期的主要工作聚焦于复杂疾病遗传分析中的统计遗传学新方法开发和应用前沿领域。其主要成果由三部分组成:1、针对多种族,大规模复杂疾病数据,开发了面向实际应用需求的全新算法和软件,提高了新算法的统计效力和计算精度,同时填补了现有基因组数据和多组学(Multi-omics)数据发展速度不匹配的鸿沟;2、基于开发的新方法,通过三百万人超大样本、多种族群体遗传分析,对烟酒成瘾等复杂疾病的遗传结构进行了深度解析,并首次对该复杂疾病遗传变异位点在不同种族人群之间的遗传效应进行了评估;3、整合多组学和药物基因组学数据,利用机器学习方法进行药物重定位(drug repurposing)分析,为复杂疾病的治疗提供了新思路。 这些开拓性研究成果不仅对于深度阐释复杂疾病的遗传机制有重要的方法创新价值,还推动基因组学和多组学在新药研发当中的应用转化前景。
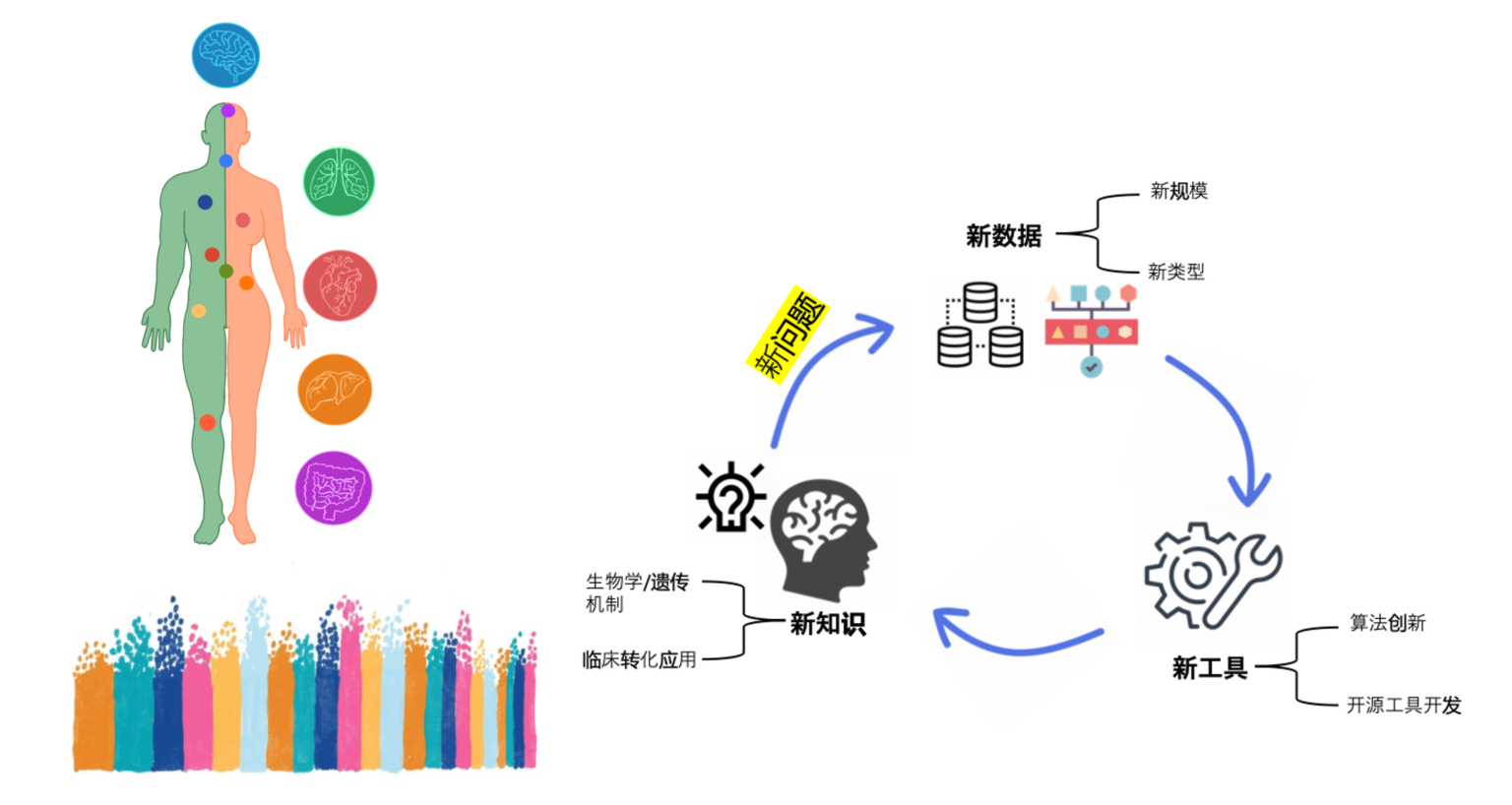
实验室将继续聚焦于统计遗传学新方法开发,机器学习和大数据技术在复杂疾病遗传分析的应用等前沿领域;结合单细胞测序技术,前沿大数据和多组学技术,开发新算法和工具,深入开展复杂疾病的关键基因鉴定和遗传结构解析,推进临床转化应用研究。具体三个方向的研究内容包括:1. 继续开展复杂疾病方向大数据分析和统计遗传新算法、新工具的开发,保持前沿领域国际合作;2. 推进新药靶点验证和药物重定位临床转化,通过机器学习方法开发,干湿结合验证,完成靶点发掘和鉴定的平台建设;3. 深入东亚人群复杂疾病(如肺纤维化,心血管疾病等)的研究,筛选东亚人群中相关疾病的特异位点;通过单细胞分析和机器学习方法,构建复杂疾病单细胞图谱,优化心血管疾病预防模型,推动精准医学和公共卫生预防研究的转化应用开发。
大规模基因关联研究(GWAS)是复杂性状和疾病研究的重要驱动力,它可以帮助揭示基因与相关性状和疾病的关系、改善疾病的诊断和预防、为后续基因功能研究提供关键线索。而随着技术和方法进步,转化医学实际应用中对于精准度和遗传多样性需求的提升,GWAS已经进入到超大规模,多祖先样本时代,这一变 化要求提高遗传研究结果质量和遗传多样性的同时,也对于研究人员的能力和经验提出了更高的要求。另一方面,多组学技术和大型公共数据库快速发展,也带来了非常多的遗传资源和应用需求,这对于我们的方法研究有着不可替代的作用。我们通过开发新的统计遗传学方法,将GWAS结果统计数据和功能基因组学多组学(Multi-omics)相结合,进一步研究生物体的遗传变异、基因表达调控以及疾病发生发展机制。
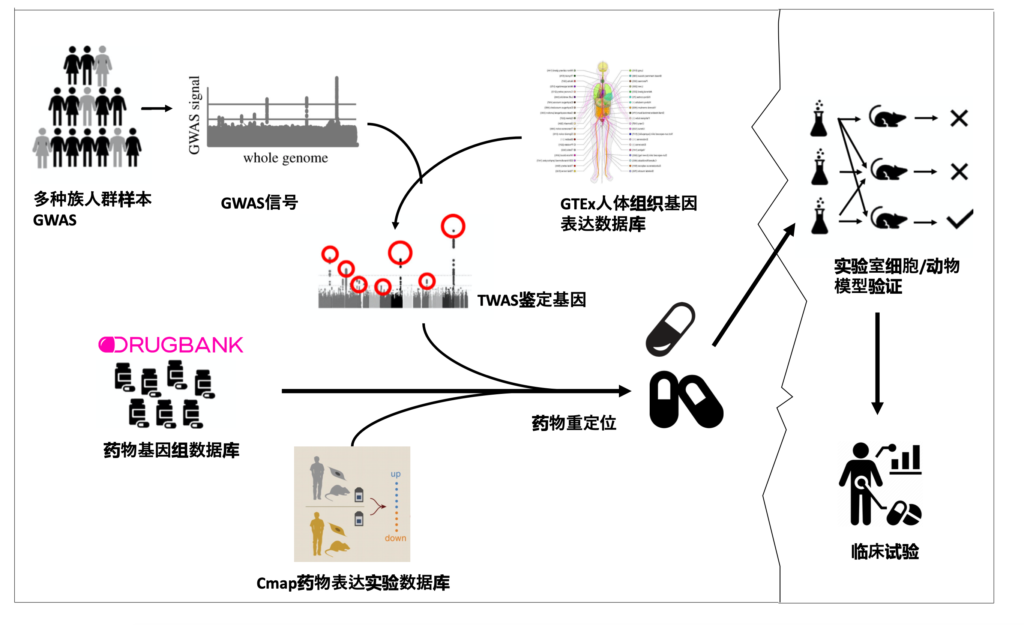
开发和运用大数据方法对复杂疾病进行遗传结构解析和生物学机制探索的最终目的是进行有效的临床转化。在这一方向,实验室会延续在新药重定位上的工作,优化基因组富集工具,整合近更多组学信息,充分开发和利用相应的机器学习方法,进一步完善计算生物学(in silico)药物重定位平台。实验室还会通过基因编辑技术开展靶点验证体系,对于筛选出的药物,通过CRISPR 基因敲除库筛选,从而找到药物作用的潜在靶标或者信号通路。对于有潜力的作用靶点,我们将与同济大学基础医学院及东方附属医院心血管病学研究中心的基础和临床研究团队开展深入合作,在iPSC多能干细胞和小鼠动物模型层面进一步深入研究,从而推进新药靶点验证和药物重定位临床转化,通过干湿结合,完成靶点发掘和鉴定的 “最后一公里”平台建设。
这一领域的核心在于利用先进的机器学习模型和大规模的单细胞基因组数据,结合空间转录组学和多组学等多种组学数据类型,来揭示复杂疾病(例如肺纤维化、心血管疾病等)中细胞的异质性和动态变化。我们在处理,获取相应的大规模单细胞数据的同时,也聚焦于开发和改进一系列计算方法。这些方法不仅利用了机器学习模型和大规模单细胞基因组数据,还包括空间转录组学和多组学等多种组学数据类型。这些方法包括但不限于应用低维方法来降低数据的复杂性,同时保持其表征重要生物学变量的能力;开发具有可解释性的深度学习模型,为生物学现象提供清晰的生物学解释。通过这些高级分析,我们希望能够更深入地理解细胞间的相互作用,以及它们如何在复杂疾病病理过程中发挥作用,从而为治疗复杂疾病提供新的策略和方向。